
一,排查步骤
1.使用top 定位到占用CPU高的进程PID 然后按shift+p按照CPU排序
top命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器
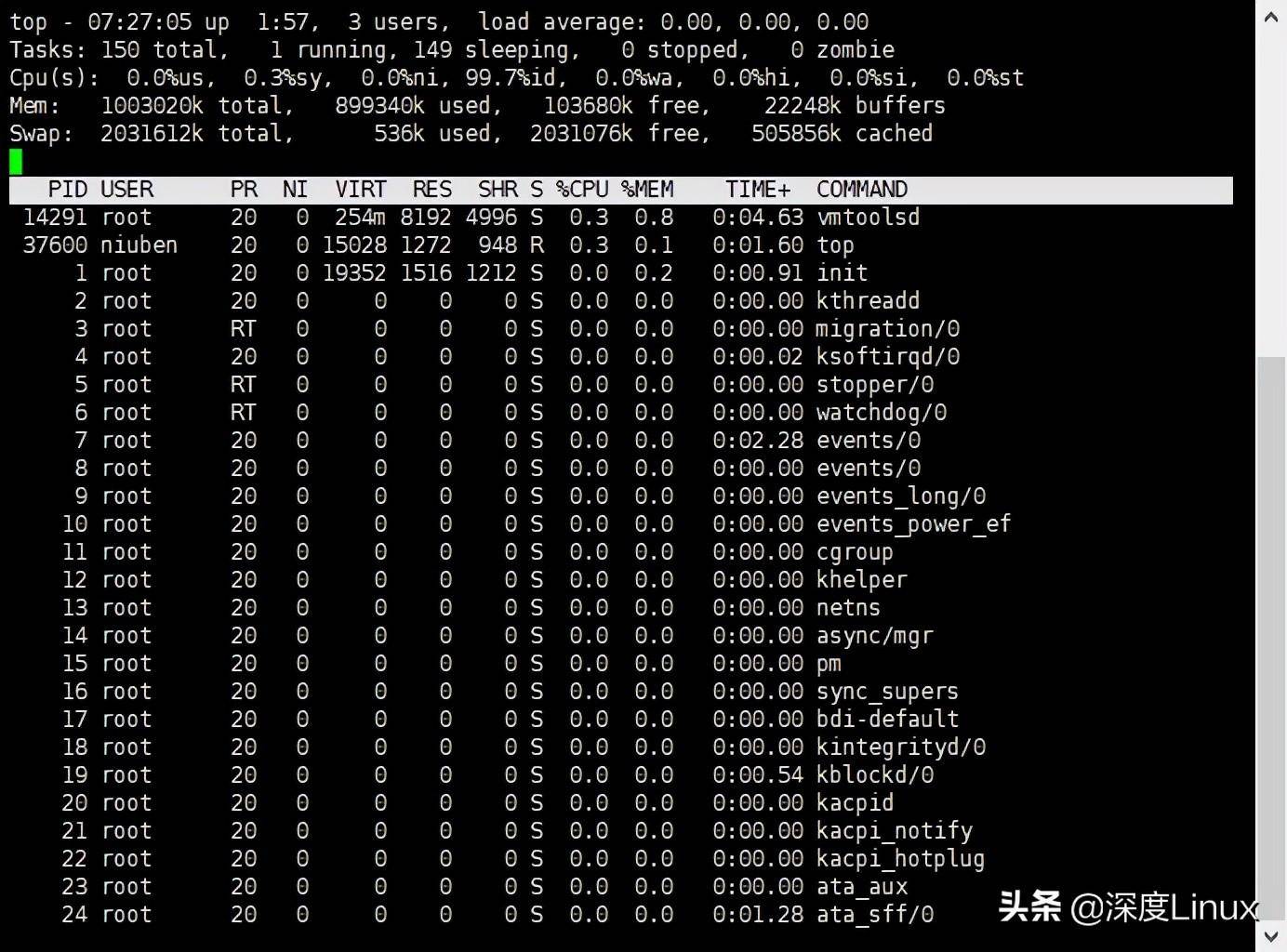

第一行,任务队列信息,同uptime 命令的执行结果
系统时间:07:27:05运行时间:up1:57min, 当前登录用户: 3 user负载均衡(uptime) loadaverage: 0.00, 0.00, 0.00average后面的三个数分别是1分钟、5分钟、15分钟的负载情况。 loadaverage数据是每隔5秒钟检查一次活跃的进程数,然后按特定算法计算出的数值。 如果这个数除以逻辑CPU的数量,结果高于5的时候就表明系统在超负荷运转了
第二行,Tasks — 任务(进程)
总进程:150 total, 运行:1 running, 休眠:149 sleeping, 停止: 0 stopped, 僵尸进程: 0 zombie
第三行,cpu状态信息
0.0%us【user space】— 用户空间占用CPU的百分比。 0.3%sy【sysctl】— 内核空间占用CPU的百分比。 0.0%ni【】— 改变过优先级的进程占用CPU的百分比 99.7%id【idolt】— 空闲CPU百分比 0.0%wa【wait】— IO等待占用CPU的百分比 0.0%hi【Hardware IRQ】— 硬中断占用CPU的百分比 0.0%si【Software Interrupts】— 软中断占用CPU的百分比
第四行,内存状态
1003020k total, 234464k used, 777824k free, 24084k buffers【缓存的内存量】
第五行,swap交换分区信息
2031612k total, 536k used, 2031076k free, 505864k cached【缓冲的交换区总量】
可用内存=free+ buffer + cached 对于内存监控,在top里我们要时刻监控第五行swap交换分区的used,如果这个数值在不断的变化, 说明内核在不断进行内存和swap的数据交换,这是真正的内存不够用了。 第四行中使用中的内存总量(used)指的是现在系统内核控制的内存数, 第四行中空闲内存总量(free)是内核还未纳入其管控范围的数量。 纳入内核管理的内存不见得都在使用中,还包括过去使用过的现在可以被重复利用的内存,内核并不把 这些可被重新使用的内存交还到free中去,因此在linux上free内存会越来越少,但不用为此担心。
更多Linux内核视频资料免费·领取后台私信【内核】自行获取。
第六行,空行
第七行以下:各进程(任务)的状态监控
PID— 进程idUSER— 进程所有者PR— 进程优先级NI— nice值。负值表示高优先级,正值表示低优先级VIRT— 进程使用的虚拟内存总量,单位kb。VIRT=SWAP+RESRES— 进程使用的、未被换出的物理内存大小,单位kb。RES=CODE+DATASHR— 共享内存大小,单位kbS—进程状态。D=不可中断的睡眠状态 R=运行 S=睡眠 T=跟踪/停止 Z=僵尸进程%CPU— 上次更新到现在的CPU时间占用百分比%MEM— 进程使用的物理内存百分比TIME+— 进程使用的CPU时间总计,单位1/100秒COMMAND— 进程名称(命令名/命令行)
详解
VIRT:virtualmemory usage 虚拟内存1、进程“需要的”虚拟内存大小,包括进程使用的库、代码、数据等2、假如进程申请100m的内存,但实际只使用了10m,那么它会增长100m,而不是实际的使用量RES:residentmemory usage 常驻内存1、进程当前使用的内存大小,但不包括swapout2、包含其他进程的共享3、如果申请100m的内存,实际使用10m,它只增长10m,与VIRT相反4、关于库占用内存的情况,它只统计加载的库文件所占内存大小SHR:sharedmemory 共享内存1、除了自身进程的共享内存,也包括其他进程的共享内存2、虽然进程只使用了几个共享库的函数,但它包含了整个共享库的大小3、计算某个进程所占的物理内存大小公式:RES– SHR4、swapout后,它将会降下来DATA1、数据占用的内存。如果top没有显示,按f键可以显示出来。2、真正的该程序要求的数据空间,是真正在运行中要使用的。top运行中可以通过 top 的内部命令对进程的显示方式进行控制。内部命令如下:s– 改变画面更新频率l– 关闭或开启第一部分第一行 top 信息的表示t– 关闭或开启第一部分第二行 Tasks 和第三行 Cpus 信息的表示m– 关闭或开启第一部分第四行 Mem 和 第五行 Swap 信息的表示N– 以 PID 的大小的顺序排列表示进程列表P– 以 CPU 占用率大小的顺序排列进程列表M– 以内存占用率大小的顺序排列进程列表h– 显示帮助n– 设置在进程列表所显示进程的数量q– 退出 tops– 改变画面更新周期
top使用方法:
使用格式: top[-][d][p][q][c][C][S][s][n]参数说明: d:指定每两次屏幕信息刷新之间的时间间隔。当然用户可以使用s交互命令来改变之。 p:通过指定监控进程ID来仅仅监控某个进程的状态。 q:该选项将使top没有任何延迟的进行刷新。如果调用程序有超级用户权限,那么top将以尽可能高的优先级运行。 S:指定累计模式。 s:使top命令在安全模式中运行。这将去除交互命令所带来的潜在危险。 i:使top不显示任何闲置或者僵死进程。 c:显示整个命令行而不只是显示命令名。
此时发现如果是Java的进程占用过高,并且一直下不来,则排查是什么线程导致占比过高。以图中进程举例,假如发现PID为31357的Java进程占CPU比一直很高,则记录下它的PID
2.查看Java进程里面的线程的占用情况
top -H -p 31357 然后按shift+p按照CPU排序
说明:-H 指显示线程,-p 是指定进程
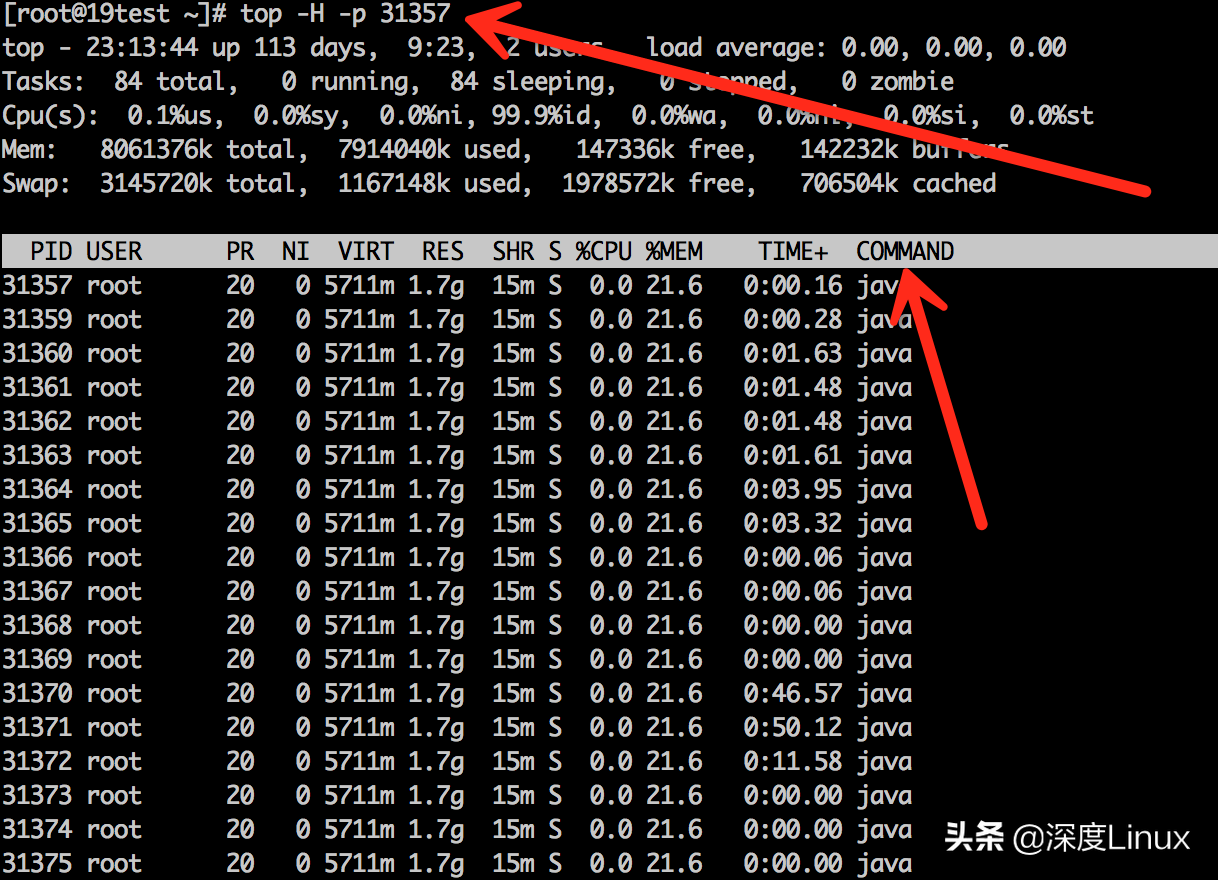
可以看到CPU占用较高的线程,记下他们的PID,假设这里31357的CPU占比一直是50%
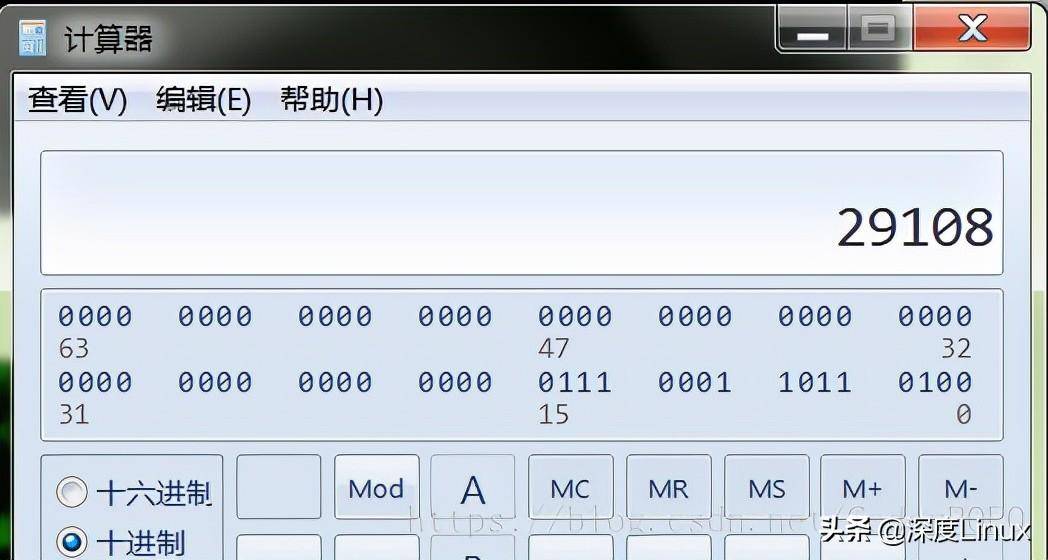
或者是再用ps -mp pid -o THREAD,tid,time 查询进程中,那个线程的cpu占用率高 记住TID
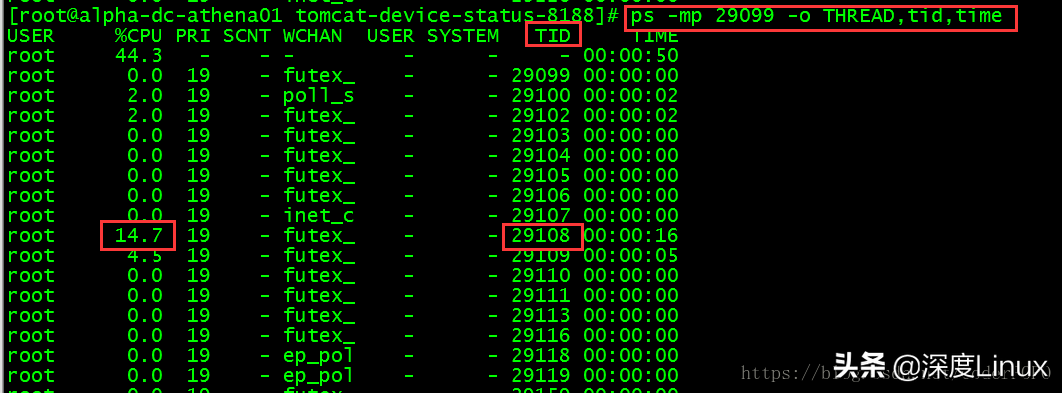
将查找到的 线程占用最高的 tid 上图中 29108 转成16进制 — 71b4
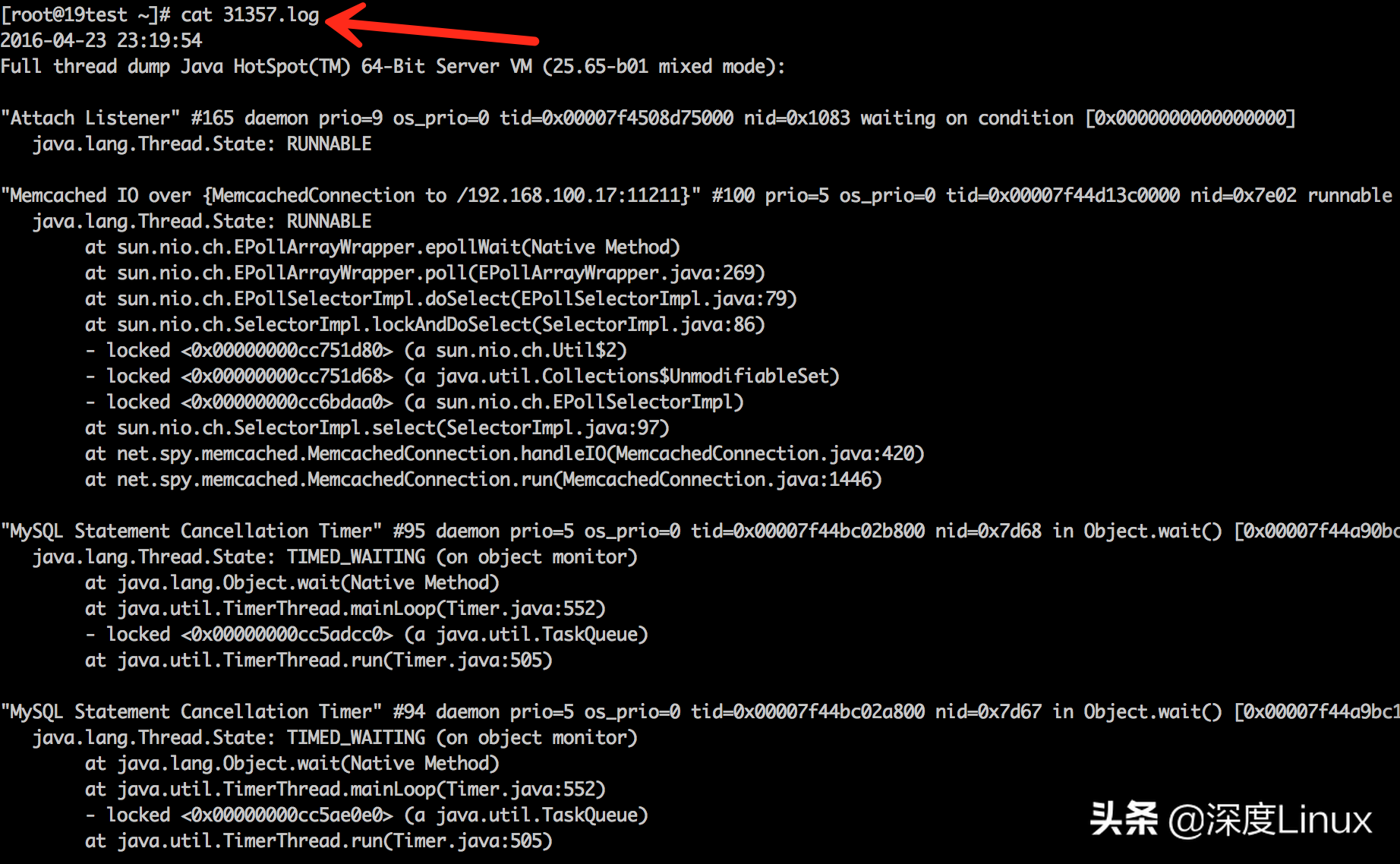
3.通过jstack命令获取占用资源异常的线程栈,可暂时保存到一个文件中查看
jstack 31357 > jstack.31357.log
以上能看到指定线程的堆栈信息。如果想看到关于线程中的锁的附加信息,可以加一个-l参数
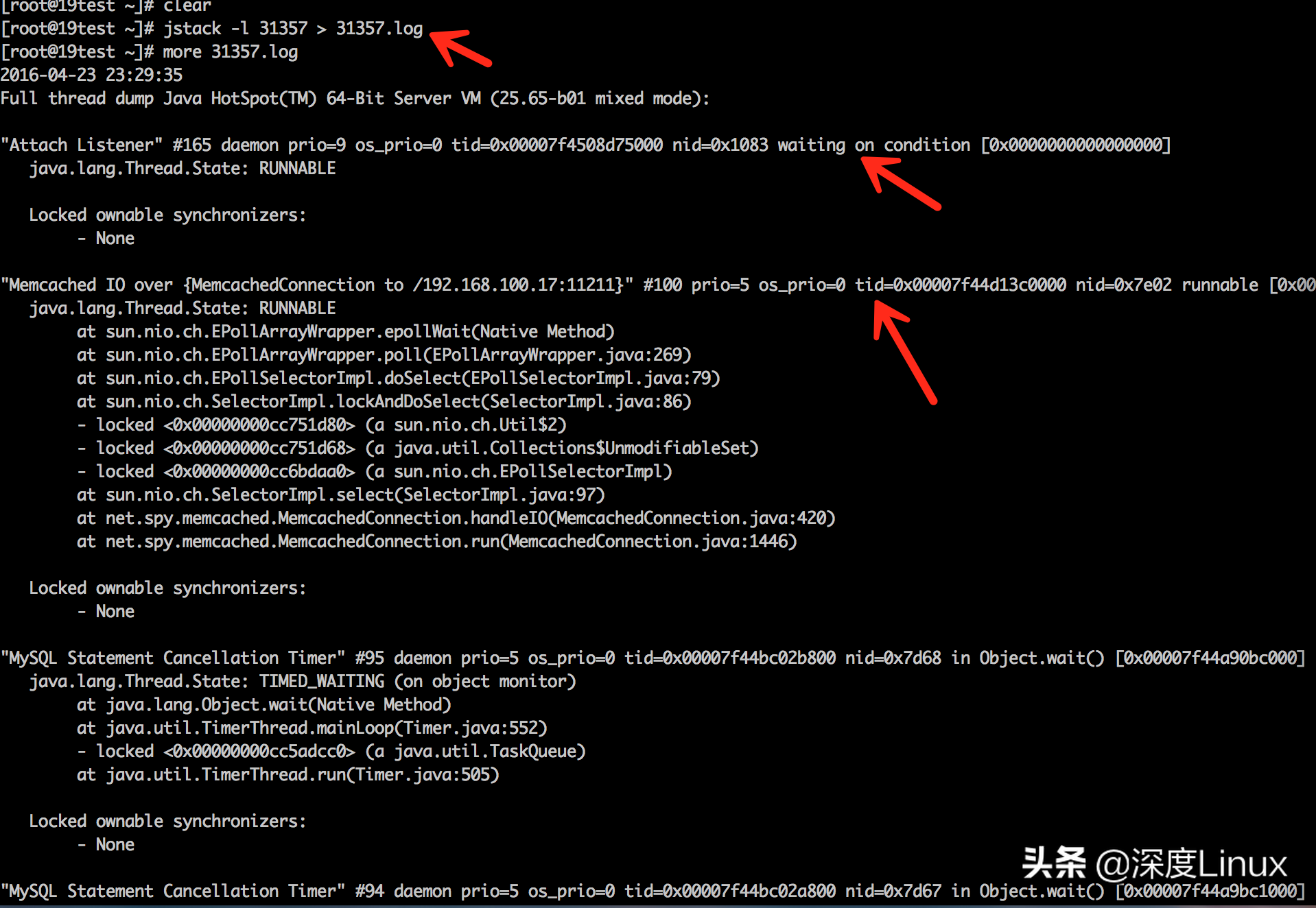
4.上面方法用于进程正常情况下的堆栈打印
用jstack -l命令没有响应,估计是CPU一直站着不能执行正常的命令,根据提示[The -F option can be used when the target process is not responding]只能放大招了。
jstack -F “PID” > jstack.“PID”.txt
吐出的实际日志结果如下:
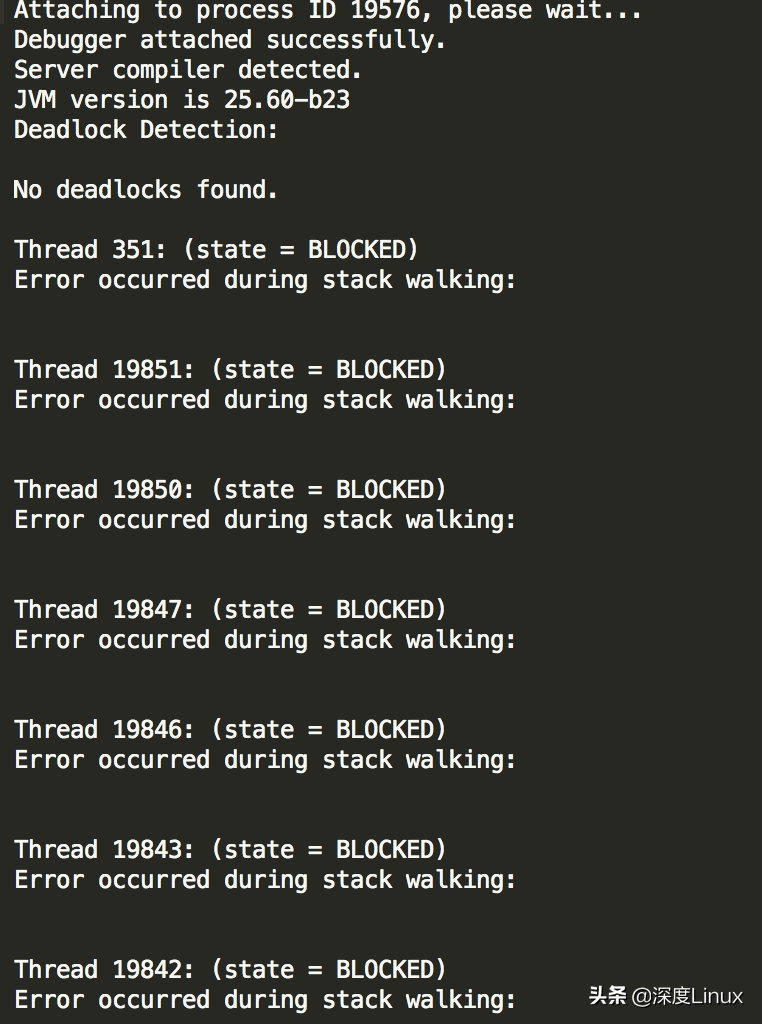
发现一大坨线程阻塞了,有用的结果在这里:
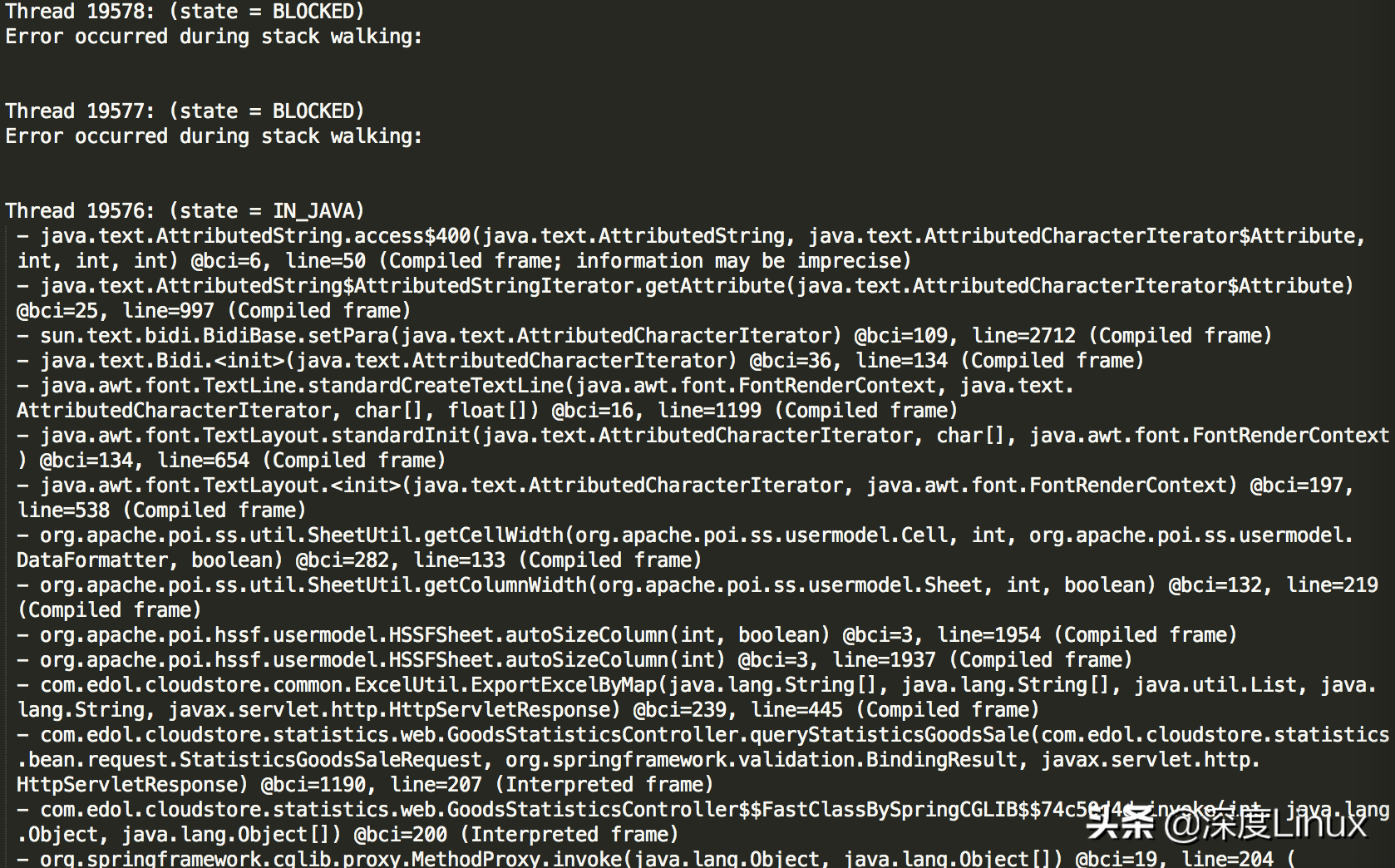
显然一直在跑的是19576这个线程,一直在执行EXCEL导出的相关方法,问题就出在这里,下面的任务就是排查这个地方的代码逻辑了。
jstack命令格式:
jstack [ option ] pid
参数说明:
- -F jstack [-l] pid无法响应时,强制打印堆栈
- -l l长列表. 打印关于锁的附加信息,例如属于java.util.concurrent的ownable synchronizers列表.
- -m 混合模式输出(包括java和本地c/c++片段)堆栈。
- pid: java应用程序的进程号
- 5jps命令查看java进程的pid更实用
命令格式
jps [ options ] [ hostid ]
参数说明:
- -m 输出传递给main方法的参数,如果是内嵌的JVM则输出为null。
- -l 输出应用程序主类的完整包名,或者是应用程序JAR文件的完整路径。
- -v 输出传给JVM的参数。
三个参数加在一起显示更详细的信息:
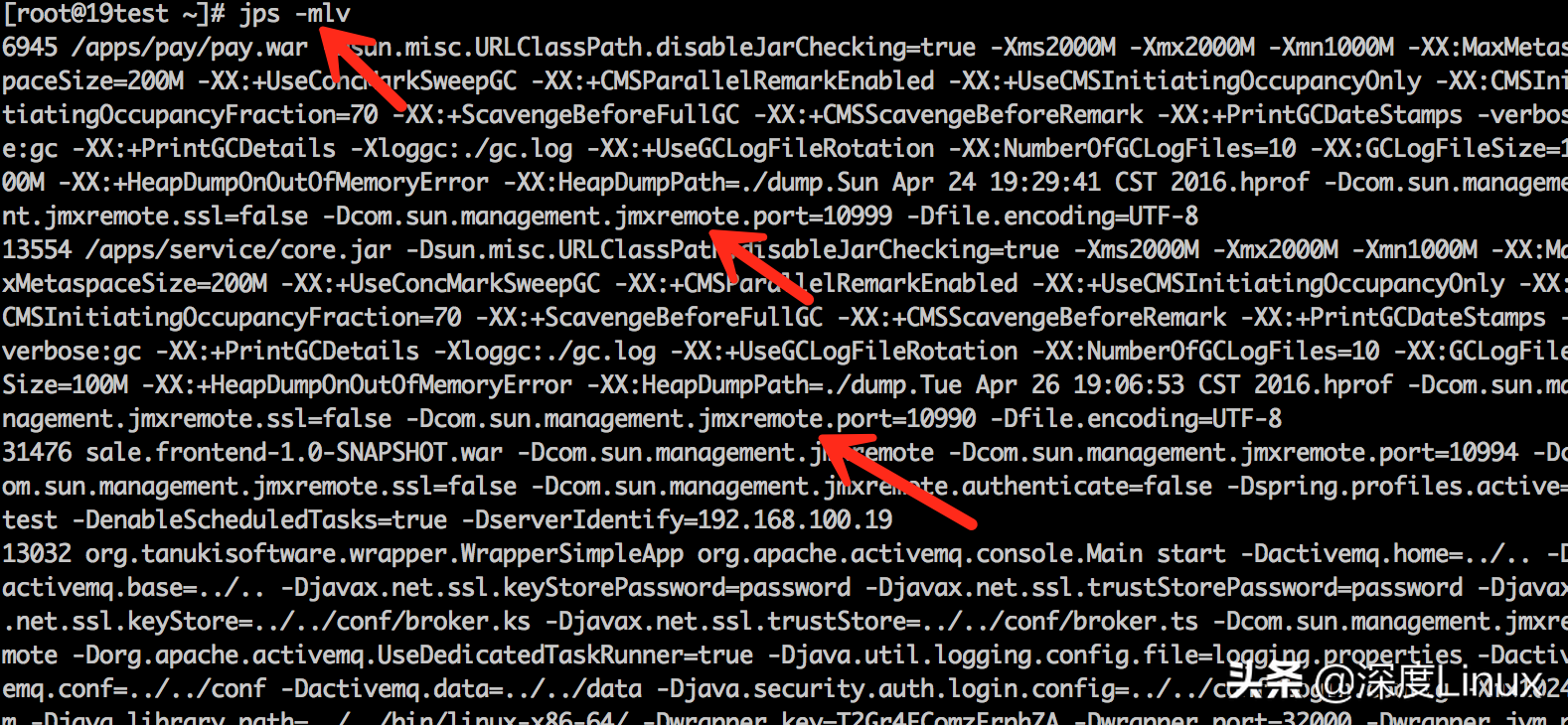
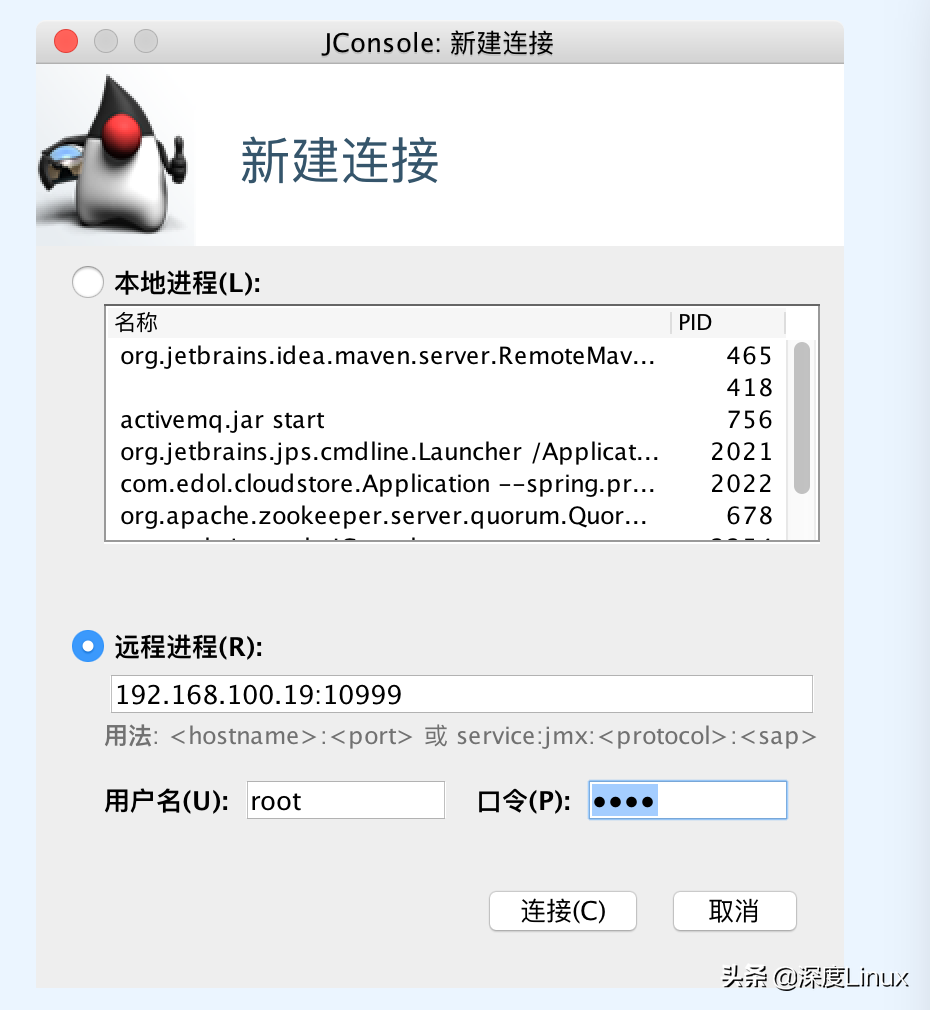
发现这些Java进程的启动参数中开放了JMX的远程端口,正常情况下可以通过jconsole远程连接过去看到JVM的日常参数。比如本地访问上图中的pay.war进程:
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
