
自打人工神经网络被引入到递归法的非线性函数中(例如人工神经网络)至今,对相关内容的使用取得了充沛的发展趋势。在这样的情况下,训练恰当的神经网络模型是创建靠谱实体模型最重要的层面。这类训练通常与”反向传播”一词联络在一起,这一专业术语对大部分初学者来讲是特别朦胧的。这也是文中所存在的价值。
反向传播是神经元网络训练的实质。它其实是根据在前一历元(即梯度下降法)中得到的误差值(即损害)对神经元网络的权重值开展调整的实践活动。适度的调节权重值可保证较低的差错率,提升实体模型的适用范围使模式更靠谱。
那麼这一全过程怎样运行的呢?使我们根据事例学习培训!
为了更好地使这一事例尽量有利于我们了解,大家只涉及到有关定义(例如损失函数、提升函数公式等)而无需多言他们,由于这种主题风格非常值得大家另起一篇文章开展详说。
最先,使我们设定实体模型部件
想像一下,大家必须训练一个深层次神经元网络。训练的目的性是建立一个实体模型,该模型应用2个键入和三个掩藏模块实行XOR(异或运算)函数公式,那样训练集看上去如下所示所显示:

除此之外,大家必须一个激活函数来明确神经元网络中每一个结点的激话值。为简洁考虑,使我们挑选一个激活函数:

大家还要一个假定函数公式来明确激活函数的键入是啥。这一变量是:

使我们挑选损失函数做为逻辑回归的一般成本函数,看上去有点儿繁杂,但事实上非常简易:

除此之外,大家将应用批处理命令梯度下降法提升函数公式,用以明确大家应当调节权重值的方位,以获取比大家目前的更低的损害。最终,学习率为0.1,使用权重将复位为1。
大家的神经元网络
使我们最终画一张大家盼望已久的神经元网络图。它应当看上去像那样:
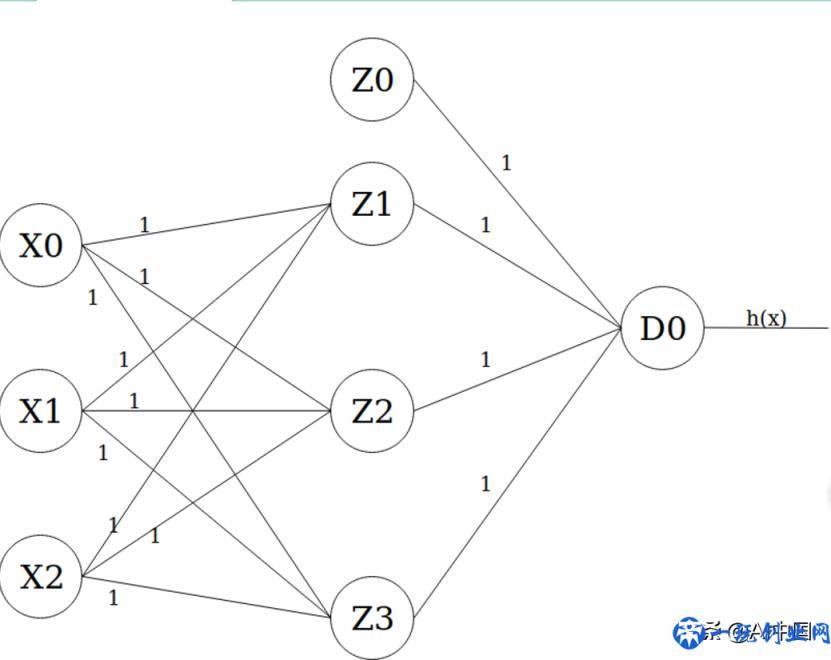
最左面的层是键入层,它将X0做为值1的偏置项,将X1和X2作为键入特点。正中间的层是第一个掩藏层,它的偏置项Z0也选值为1。最终,輸出层只有一个输出模块D0,其激话值是实体模型的具体輸出(即h(x)) 。
如今大家往前散播
现在是将信息内容从一个层前馈控制到另一个层的那时候了。这要通过2个流程,根据互联网中的每一个连接点/模块:
1. 应用大家以前界定的h(x)函数公式获得特殊企业键入的权重计算和。
2.将大家从过程1获得的值插进大家的激活函数(本例中为f(a)= a)并应用大家获得的激话值(即激活函数的輸出)做为联接键入特点的下一层中的连接点。
一定要注意,企业X0,X1,X2和Z0没有联接到他们并任给予键入的企业。因而,以上流程不容易发生在这种连接点中。可是,针对其他的连接点/模块,训练集中化第一个键入样版的全部神经元网络全是这种的:

别的企业也是如此:


如前所述,最后企业(D0)的激话值(z)是全部实体模型的激话值(z)。因而,大家的模型预测键入集{0,0}的输入输出为1。测算现阶段梯度下降法的损害/成本费如下所示:

actual_y值来源于训练集,而predict_y值是大家实体模型出现的值。因此此次梯度下降法的成本费用是-4。
那麼反向传播在哪儿呢?
依据人们的事例,大家如今有一个实体模型沒有得出确切的预测分析(它给大家的值是4而不是1),这归因于它的权重值并未调节(他们都相当于1)。大家也是有损害,即-4。反向传播便是以那样一种方法向后传送这类损害,我们可以依据这类方法调整权重值。提升函数公式(在人们的案例中为梯度下降法)将协助人们寻找权重值。那就由大家现在开始!
应用下列作用开展前馈控制:


随后利用这种函数公式的偏导数产生反方向意见反馈。不用通过经过推论这种函数公式的全过程。大家必须明白的是,上边的函数公式将遵循:

在其中Z是人们从前馈控制流程中的激活函数测算中得到的z值,而delta是涂层中企业的损害。
我明白有很多信息内容一次性就能消化吸收,但我建议你花一点时间,真真正正掌握每一步发生什么事,随后再砥砺前行。
测算增加量
如今大家必须寻找神经元网络中每一个模块/连接点的耗损。这是为什么呢?大家那样想,深度神经网络实体模型抵达的每一次损害事实上是由全部连接点累积一个数据造成的。因而,大家必须找到哪个连接点对各层中的绝大多数损害承担,那样大家就可以根据授予它更小的权重来处罚它,进而降低实体模型的总损害。
测算每一个模块的增加量很有可能会有什么问题。可是,感激吴恩达老先生,他给了咱们全部事儿的近道公式计算:

在其中delta_0,w和f’(z)的值是同样企业的值,而delta_1是权重计算连接另一侧的企业损害。例如:
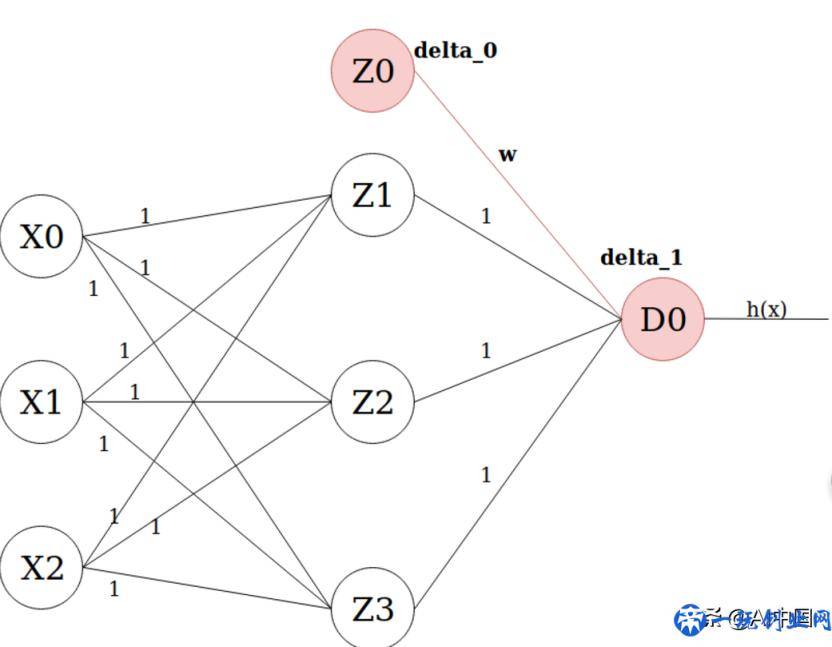
你能那样想,为了更好地得到连接点的损害(例如Z0),大家将其相应的f’(z)的值乘于它在下一层(delta_1)联接的连接点的损害,再乘于联接2个连接点的链接的权重值。
这恰好是反向传播的原理。我们在每一个模块开展delta测算流程,将损害反向传播到神经元网络中,并找到每一个连接点/模块的损害。
使我们测算一下这种增加量!

这里有一些常见问题:
- 最后单位的损失(即D0)相当于全部实体模型的损失。这是由于它是輸出单位,它的损失是全部单位的累计损失,就像大家以前说的那般。
- 无论键入(即z)等于什么,函数公式f’(z)一直得出值1。这是由于如前所述,偏导数如下所示:f’(a)= 1
- 键入连接点/单位(X0,X1和X2)沒有delta值,由于这种连接点在人工神经网络中控制不了。他们仅做为数据和神经元网络中间的一个连接。
升级权重值
如今剩余的是升级我们在神经元网络中的使用权重。这遵循大批量梯度下降法公式计算:

在其中W是手头上的权重值,alpha是学习率(在人们的案例中是0.1),J’(W)是成本函数J(W)相对性于W的偏导数。再度注重,大家不用开展数学运算。因而,使我们应用吴恩达老先生的函数公式的偏导数:

在其中Z是根据前向散播得到的Z值,delta是权重计算连接另一端的单位损失:
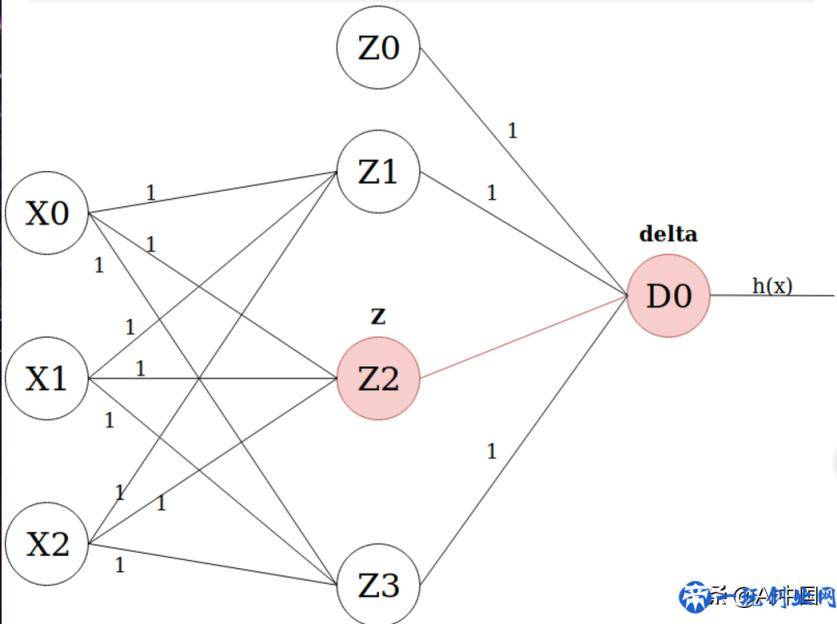
如今用我们在每一步得到的偏导数值,和大批量梯度下降法权重值升级使用权重。非常值得指出的是,键入连接点(X0,X1和X2)的Z值各自相当于1,0,0。1是偏置模块的值,而0其实是来源于数据的特点键入值。最终要留意的是,沒有特殊的次序来升级权重值。你能依照你愿意的一切次序升级他们,如果你不容易在同一次梯度下降法中不正确地升级一切权重值2次。
为了更好地测算新的权重值,使我们得出神经元网络名字中的连接:
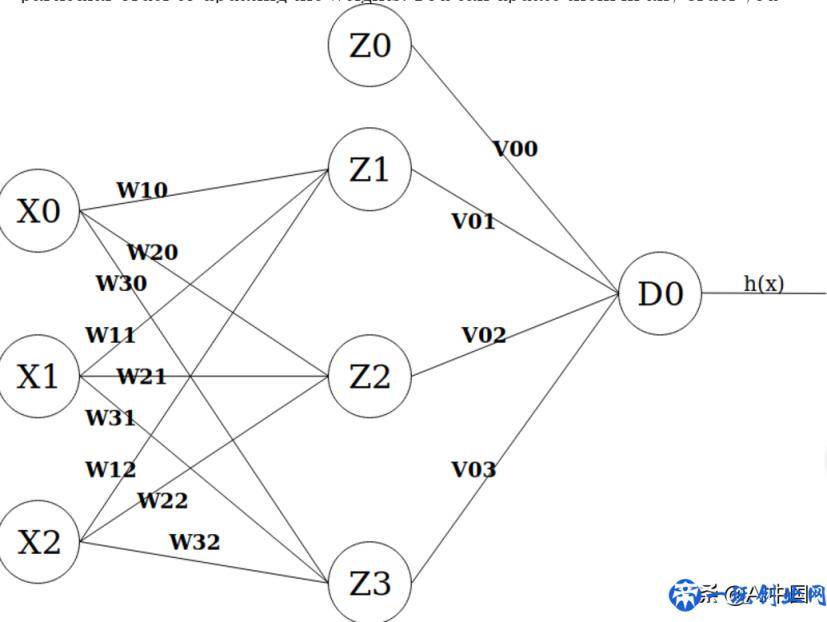
新的权重计算方式如下所示:


必须留意的是,实体模型都还没恰当练习,由于人们只根据练习密集的一个样品开展反向传播。大家为样版进行了全部大家能做的一切,这可以形成一个有着更高精密的实体模型,尝试贴近每一步的最少损失/成本费。
要是没有合理的方式,人工神经网络身后的基础理论很难把握。在其中一个事例便是反向传播,其实际效果在大部分现实世界的深度神经网络应用软件里都是可以预料的。反向传播仅仅将总耗损传到神经元网络的一种方法,以便捷大家掌握每一个结点的损失量,并接着根据为连接点给予更高一些偏差,从而应用损失降到最低的方法来升级权重值,相反也是。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。

