
数据剖析是对数据开展摄入、变换和数据可视化的全过程,用于挖掘对业务流程管理决策有价值的洞悉。
在过去的的十年中,愈来愈多的数据被搜集,顾客期待从数据中取得更有價值的洞悉。她们还期待能在很短的時间内(乃至即时地)得到这类洞悉。她们期待有越多的临时性查询便于回应大量的业务流程问题。为了更好地解答这种问题,顾客必须更强劲、更高效率的系统软件。
批处理命令通常涉及到查询很多的冷数据。在批处理命令中,很有可能要几小时才可以得到业务流程问题的回答。例如,你也许会应用批处理命令在月底形成信用卡账单汇报。
即时的流解决通常涉及到查询少许的热数据,只必须很短的时间段就可以获得回答。例如,根据MapReduce的系统软件(如Hadoop)便是适用批处理命令工作种类的服务平台。数据库房是适用查询模块种类的服务平台。
流数据解决必须摄入数据编码序列,并依据每条数据纪录开展增加量升级。通常,他们摄入持续造成的数据流,如计量检定数据、监控器数据、财务审计日志、调节日志、网址点一下流及其机器设备、工作人员和货品的位置跟踪事情。
图13-6展现了应用AWS云技术栈解决、变换并数据可视化数据的数据湖生产流水线。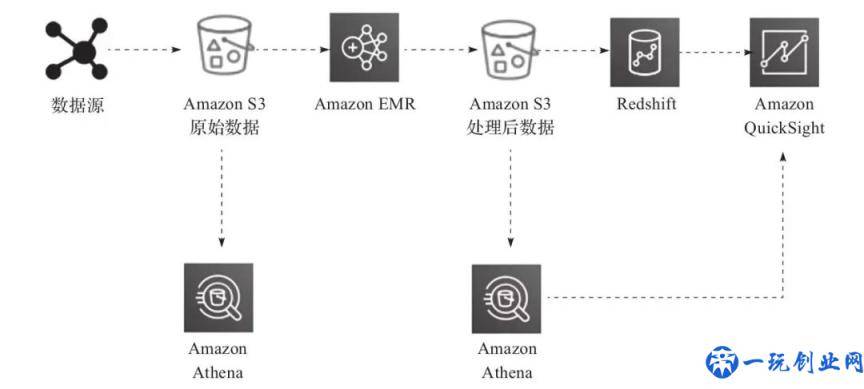
▲图13-6 应用数据湖ETL生产流水线解决数据
在这儿,ETL生产流水线应用Amazon Athena对存放在Amazon S3中的数据开展临时性查询。从各种各样数据源(例如,Web网站服务器)摄入的数据会形成日志文档,并长久储存在S3。随后,这种文档将被Amazon Elastic MapReduce(EMR)变换和清理成造成洞悉需要的方式并载入到Amazon S3。
用COPY指令将这种变换后的文档数据加载到Amazon Redshift,并应用Amazon QuickSight开展数据可视化。应用Amazon Athena,你能在数据储存时立即从Amazon S3中查询,还可以在数据变换后查询(从汇聚后的数据集)。你能在Amazon QuickSight中对数据开展数据可视化,还可以在没有更改目前数据步骤的情形下轻轻松松查询这种文档。
下列是一些最流行的可以协助你对大量数据开展变换和处置的数据解决技术性:
01 Apache Hadoop

Apache Hadoop应用分布式系统解决构架,将每日任务分配到网络服务器集群上开展解决。派发到集群网络服务器上的每一项每日任务都能够在任何一台网络服务器上运作或再次运作。集群网络服务器通常应用HDFS将数据储存到当地开展解决。
在Hadoop架构中,Hadoop将大的工作切分成离散变量的每日任务,并行计算。它能在总数巨大的Hadoop集群中完成大范围的弹性。它还制定了容错机制作用,每一个工作中连接点都是会按时向主连接点汇报自身的情况,主连接点可以将工作中负荷从沒有大力支持的集群分配出来。
Hadoop最经常使用的架构有Hive、Presto、Pig和Spark。
02 Apache Spark

Apache Spark是一个运行内存解决架构。Apache Spark是一个规模性并行计算系统软件,它有不一样的电动执行器,可以将Spark工作分拆,并行执行每日任务。为了更好地提升操作的并行度,可以在集群中提升连接点。Spark适用批处理命令、互动式和流式的数据源。
Spark在工作实行环节中的任何环节都应用有向无环图(Directed Acyclic Graph,DAG)。DAG可以追踪工作流程中数据的变换或数据承袭状况,并将DataFrames储存在存储空间中,合理地降到最低I/O。Spark还具备系统分区认知作用,以防止互联网密集式的数据改组。
03 Hadoop客户体验
Hadoop用户体验(Hadoop User Experience,HUE)使你能根据基于电脑浏览器的操作界面而不是命令在集群上开展查询并运作脚本制作。
HUE在操作界面中给予了最多见的Hadoop部件。它可以根据电脑浏览器查询和追踪Hadoop实际操作。好几个客户可以登陆HUE的门户网浏览集群,管理人员可以手动式或根据LDAP、PAM、SPNEGO、OpenID、OAuth和SAML2验证管理方法浏览。HUE容许你即时查询日志,并给予一个元存储系统器来实际操作Hive元储存內容。
04 Pig

Pig通常用以解决很多的初始数据,随后再以结构型文件格式(SQL表)储存。Pig适用ETL实际操作,如数据认证、数据载入、数据变换,及其以多种多样文件格式组成来源于众多由来的数据。除开ETL,Pig还适用关联实际操作,如嵌入数据、联接和分类。
Pig脚本制作可以应用非结构型和半结构化数据(如Web服务端日志或点一下流日志)做为键入。比较之下,Hive一直规定键入数据达到一定方式。Pig的Latin脚本制作包括有关怎样过虑、分类和联接数据的命令,但Pig并不准备变成一种查询语言表达。Hive更合适查询数据。Pig脚本制作依据Pig Latin语言的命令,编译程序并运作以变换数据。
05 Hive

Hive是一个开源系统的数据库房和查询包,运作在Hadoop集群以上。SQL是一项十分普遍的专业技能,它可以协助精英团队轻轻松松过度到大数据全球。
Hive应用了一种类似SQL的语言表达,称为Hive Query语言表达(Hive Query Language,HQL),这导致在Hadoop系统软件中查询和解决数据越来越很容易。Hive抽象化了用Java等编号语言表达程序编写来实行剖析工作的多元性。
06 Presto
Presto是一个相近Hive的查询模块,但它的速率更快。它适用ANSI SQL规范,该标准非常容易学习培训,也是最流行的专业技能集。Presto适用繁杂的查询、联接和汇聚作用。
与Hive或MapReduce不一样,Presto在存储空间中实行查询,降低了延迟时间,提升了查询特性。在挑选 Presto的网络服务器容积时要当心,因为它必须有充足的运行内存。内存溢出时,Presto工作将重启。
07 HBase

HBase是做为开源系统Hadoop新项目的一部分开发设计的NoSQL数据库。HBase运作在HDFS上,为Hadoop生态体系给予非关联型数据库。HBase有利于将很多数据缩小并以列式文件格式储存。与此同时,它还带来了迅速搜索作用,由于在其中较大一部分数据被缓存文件在存储空间中,集群案例储存也一起在应用。
08 Apache Zeppelin
Apache Zeppelin是一个创建在Hadoop系统软件之中的用以数据剖析的根据Web的编辑软件,又被称作Zeppelin Notebook。它的后台管理语言表达应用了编译器的定义,容许一切语言表达连接Zeppelin。Apache Zeppelin包含一些主要的数据图表和透视图。它非常灵活,一切语言表达后台管理的一切輸出結果都能够被鉴别和数据可视化。
09 Ganglia
Ganglia是一个Hadoop集群监控器专用工具。可是,你需要在运作时在集群上安裝Ganglia。Ganglia UI运作在主连接点上,你能根据SSH浏览主连接点。Ganglia是一个开源软件,致力于监控器集群而不危害其特性。Ganglia可以协助查验集群中每个网络服务器的性能指标及其集群总体的特性。
10 JupyterHub
JupyterHub是一个多客户的Jupyter Notebook。Jupyter Notebook是数据生物学家开展数据工程项目和ML的最流行的设备之一。JupyterHub服务端为每一个客户给予根据Web的Jupyter Notebook IDE。好几个客户可以一起应用她们的Jupyter Notebook来编程和实行编码,进而开展探究性数据剖析。
11 Amazon Athena

Amazon Athena是一个互动式查询服务项目,它应用规范ANSI SQL英语的语法在Amazon S3对象存储上运作查询。Amazon Athena创建在Presto以上,并扩大了做为托管服务的临时性查询作用。Amazon Athena元数据储存与Hive元数据存储的工作方式同样,因而你能在Amazon Athena中应用与Hive元数据储存同样的DDL句子。
Athena是一个无网络服务器的托管服务,这代表全部的基础建设和手机软件运维管理都由AWS承担,你能立即在Athena的根据Web的自定义中实行查询。
12 Amazon Elastic MapReduce
Amazon Elastic MapReduce(EMR)实质上是云端的Hadoop。你能应用EMR来充分发挥Hadoop架构与AWS云的强悍作用。EMR适用全部最流行的开源框架,包含Apache Spark、Hive、Pig、Presto、Impala、HBase等。
EMR提供了解耦的估算和储存,这代表着无须让大中型的Hadoop集群不断运行,你能实行数据交换并将結果载入到分布式锁的Amazon S3储存中,随后关掉网络服务器。EMR提供了自行伸缩式功能,给你节约了组装和升级网络服务器的各种各样系统的管理方法花销。
13 AWS Glue
AWS Glue是一个代管的ETL服务项目,它有利于完成数据处理、备案和人工神经网络变换以搜索重复记录。AWS Glue数据信息文件目录与Hive数据信息文件目录兼容,并在各种各样数据库(包含关系数据库、NoSQL和文档)间提供集中化的元数据储存库。
AWS Glue创建在Spark集群以上,并将ETL做为一项托管服务提供。AWS Glue能为普遍的测试用例形成PySpark和Scala编码,因而不用重新开始撰写ETL编码。
Glue工作受权功能可解决工作中的一切不正确,并提供日志以掌握最底层管理权限或数据类型问题。Glue提供了工作流引擎,根据简洁的拖放功能协助你创建自动化技术的数据信息生产流水线。
总结
数据统计分析和解决是一个巨大的主题,非常值得独立写一本书。文中归纳地讲解了数据处理的时兴专用工具。也有大量的专用和开源系统专用工具可选择。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。

