
小伙伴们,小伙伴们好!
热烈欢迎各位赶到数据信息与智能化小课堂,今日的教学内容为《Hadoop生态系统》。
此次內容将分成四个一部分为我们解读:Hadoop介绍、Hadoop的特性、Hadoop1.0与2.0的区别、Hadoop生态系统的构成。
1. Hadoop介绍
说到hadoop迫不得已提及一个人——Doug Cutting,他是hadoop鼻祖、Apache Lucene的创办人。
Hadoop是Apache集团旗下的开放源码的分布式存储服务平台,它可以运作在电子计算机群集以上,给予靠谱的、可拓展的分布式存储作用。Hadoop的核心内容是分布式文件系统(HDFS)和并行处理程序编程架构MapReduce。
Hadoop与三遍毕业论文紧密联系:
① 2003年,谷歌公布的分布式文件系统GFS的毕业论文,可以用以处理海量信息储存的问题。
② 2004年,谷歌公布了MapReduce的毕业论文,可以用以处理海量信息测算的问题。
③ 2006年,谷歌公布了BigTable的毕业论文,它是以GFS为最底层数据储存的分布式数据库系统软件。
| 年代 | 谷歌 |
| 2003年 | 谷歌分布式文件系统GFS的毕业论文 |
| 2004年 | 谷歌MapReduce的论文 |
| 2006年 | 谷歌BigTable的毕业论文 |
GFS、MapReduce、BigTable便是人们常常说的“三辆马车”。
Hadoop与这三篇毕业论文的相互关系是如此的:
Hadoop中的HDFS是GFS的开源系统完成;Hadoop中的MapReduce是谷歌MapReduce的开源系统完成;Hadoop中的HBase是谷歌BigTable的开源系统完成。
2. hadoop的特性
① 混合开发性:hadoop是根据java语言开发设计的,有不错的混合开发性,可以运作在Linux平台上;
② 可靠性高:hadoop中的HDFS是分布式文件系统,可以将海量信息遍布多余储存在不一样的设备连接点上,即使是某一设备团本上产生常见故障,别的的设备团本也可以正常的运作;
③ 高容错性:HDFS把把文档遍布储存在许多不一样的设备连接点上,能完成全自动储存好几个团本,因而某一连接点上的工作不成功后也可以完成全自动分配;
④ 精确性:hadoop的关键部件HDFS和MapReduce,一个负责分布式系统一个负责分布式解决,可以解决PB级其他数据信息;
⑤ 成本低与高拓展:hadoop在便宜的电子计算机群集上就可以运作,因而成本费非常低,而且可以扩大到好几千个电子计算机连接点上,进行大数据的存放和测算。
3. Hadoop1.0和2.0的区别
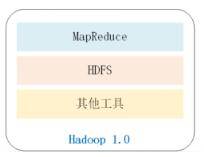
Hadoop1.0与2.0的较大区别便是,hadoop2.0在1.0的基本上提升了一个yarn架构。
① Hadoop1.0的构成包括:hdfs、MapReduce和其它部件。
Hdfs负责数据储存,MapReduce负责数据信息测算及其資源生产调度(在开展数据处理方法的过程中是要开展资源配置的,例如用是多少CPU、运行内存、硬盘这些)
② Hadoop2.0的构成包括:hdfs、MapReduce、yarn和其它部件。
Hdfs负责数据储存,MapReduce负责数据信息测算,yarn负责資源生产调度

4. Hadoop生态系统的构成
Hadoop除开有两个关键部件HDFS 和MapReduce以外,还包含yarn、hbase、hive、pig、mahout、zookeeper、sqoop、flume、Apache Ambari等作用部件。
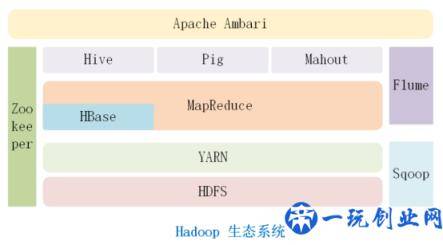
① HDFS:hadoop分布式文件系统,可以运作在中大型的便宜电子计算机群集上,并且以流的方法载入和解决大量文档。HDFS要熟练掌握的基本概念有NameNode、DataNode和Secondary Namenode,后边会出现专业章节目录为我们解读。
② Yarn:資源生产调度和监管架构,在其中包括ResourceManager、ApplicationMaster和NodeManager。ResourceManager负责资源优化配置,ApplicationMaster负责线程同步和监控器,NodeManager 负责执行任务。
③ MapReduce:分布式系统并行处理程序编程架构,核心内容是“分而治之”。MapReduce=Map Reduce。Map函数公式负责分块的工作中,reduce函数负责融合归约。
④ HBase:是谷歌bigtable的开源系统完成。它区别于传统式关系型数据库的一点是:根据列式储存。传统式数据库查询是根据行的储存,而HBase是根据列的储存,具备高效率稳定的解决关系型数据库的工作能力。
⑤ Hive:是根据hadoop的数据库管理专用工具,能对数据开展简易解决,它有着相近SQL語言的数据库架构hive-sql。
⑥ Pig:是一种数据流分析语言表达,给予了相近sql的语言表达pig latin,可以用于查看半非结构化数据集。
⑦ Mahout:是Apache的一个开源软件,给予一些归类、聚类分析、过虑这些人工神经网络行业经典算法。
⑧ Zookeeper:是个高效率的靠谱的分布式系统协调工作系统软件。
⑨ Sqoop:sql-to-hadoop的简称,含意便是在关系型数据库与hadoop中间做数据传输。
⑩ Flume:大量日志搜集、汇聚、传送系统软件。它也可以对数据资料开展简洁的解决。
⑪ Apache Ambari:是一种适用Apache Hadoop群集的安裝、布署、配备和管控的专用工具。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。

