
TensorFlow-TensorRT (TF-TRT) 是 TensorFlow 和 TensorRT 的集成,可在 TensorFlow 生态系统中对 NVIDIA GPU 的推理进行优化。它提供的简单 API 能够轻而易举地在使用 NVIDIA GPU 时带来巨大性能提升。该集成使 TensorRT 中的优化可被使用,并在遇到 TensorRT 不支持的模型部分算子时提供到原生 TensorFlow 的回退。
- TensorRT
https://developer.nvidia.com/tensorrt
先前关于 TF-TRT 集成的文章中,我们介绍了 TensorFlow 1.13 和更早版本的工作流。这篇文章将介绍 TensorFlow 2.x 中的 TensorRT 集成,并展示最新 API 的示例工作流。如果您刚接触此集成,这并无大碍,本文包含所有入门所需的信息。与 NVIDIA T4 GPU 上的使用原生 TensorFlow 推理相比,使用 TensorRT 集成可以将性能提高 2.4 倍。
- 文章
https://blog.tensorflow.org/2019/06/high-performance-inference-with-TensorRT.html
TF-TRT 集成
启用 TF-TRT 后,第一步解析经过训练的模型,将计算图分为 TensorRT 支持的子计算图和不支持的子计算图。然后,每个 TensorRT 支持的子计算图都被封装在一个特殊的 TensorFlow 运算 (TRTEngineOp) 中。第二步,为每个 TRTEngineOp 节点构建一个优化的 TensorRT 引擎。TensorRT 不支持的子计算图保持不变,由 TensorFlow 运行时处理。如图 1 所示。
- TF-TRT
https://github.com/tensorflow/tensorrt - TensorRT 支持的
https://docs.nvidia.com/deeplearning/frameworks/tf-trt-user-guide/index.html?ncid=partn-31097#supported-ops
TF-TRT 既可以利用 TensorFlow 的灵活性,同时还可以利用可应用于 TensorRT 支持的子计算图的优化。TensorRT 只优化和执行计算图的一部分,剩余的计算图由 TensorFlow 执行。
在图 1 所示推理示例中,TensorFlow 执行了 Reshape 运算和 Cast 运算。然后,TensorFlow 将预构建的 TensorRT 引擎 TRTEngineOp_0 的执行传递至 TensorRT 运行时。
图 1:计算图分区和在 TF-TRT 中构建 TRT 引擎的示例
工作流
在这一部分中,我们将通过一个示例研究典型的 TF-TRT 工作流。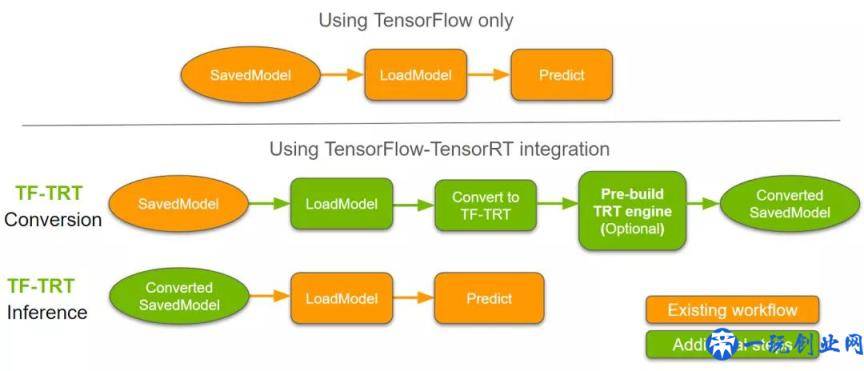
图 2仅在 TensorFlow中执行推理,以及在TensorFlow-TensorRT中使用转换后的SavedModel执行推理时的工作流图
图 2 显示了原生 TensorFlow 中的标准推理工作流,并与 TF-TRT 工作流进行了对比。SavedModel 格式包含共享或部署经过训练的模型所需的所有信息。在原生 TensorFlow 中,工作流通常涉及加载保存的模型并使用 TensorFlow 运行时运行推理。在 TF-TRT 中还涉及一些额外步骤,包括将 TensorRT 优化应用到 TensorRT 支持的模型子计算图,以及可选地预先构建 TensorRT 引擎。
- SavedModel
https://tensorflow.google.cn/guide/saved_model
首先,创建一个对象来存放转换参数,包括一个精度模式。精度模式用于指示 TF-TRT 可以用来实现 TensorFlow 运算的最低精度(例如 FP32、FP16 或 INT8)。然后创建一个转换器对象,它从保存的模型中获取转换参数和输入。注意,在 TensorFlow 2.x 中,TF-TRT 仅支持以 TensorFlow SavedModel 格式保存的模型。
接下来,当我们调用转换器 convert() 方法时,TF-TRT 将用 TRTEngineOps 替换 TensorRT 兼容的部分以转换计算图。如需在运行时获得更好的性能,可以使用转换器 build() 方法提前创建 TensorRT 执行引擎。build() 方法要求,在构建优化的 TensorRT 执行引擎之前必须已知输入数据形状。如果输入数据形状未知,则在输入数据可用时,可以在运行时构建 TensorRT 执行引擎。要在 GPU 上构建 TensorRT 执行引擎,GPU 的设备类型应与执行推理的设备类型相同,因为构建过程特定于 GPU。例如,为 NVIDIA A100 GPU 构建的执行引擎将无法在 NVIDIA T4 GPU 上运行。
- build()
https://tensorflow.google.cn/api_docs/python/tf/experimental/tensorrt/Converter
最后,可以调用 save 方法将 TF-TRT 转换的模型保存到磁盘。本部分提及的工作流步骤的对应代码如以下代码块所示:
from tensorflow.python.compiler.tensorrt import trt_convert as trt
# Conversion Parameters
conversion_params = trt.TrtConversionParams(
precision_mode=trt.TrtPrecisionMode.<FP32 or FP16>)
converter = trt.TrtGraphConverterV2(
input_saved_model_dir=input_saved_model_dir,
conversion_params=conversion_params)
# Converter method used to partition and optimize TensorRT compatible segments
converter.convert()
# Optionally, build TensorRT engines before deployment to save time at runtime
# Note that this is GPU specific, and as a rule of thumb, we recommend building at runtime
converter.build(input_fn=my_input_fn)
# Save the model to the disk
converter.save(output_saved_model_dir)- save
https://tensorflow.google.cn/api_docs/python/tf/experimental/tensorrt/Converter
由以上代码示例可知,build() 方法需要一个与输入数据形状对应的输入函数。输入函数示例如下所示:
# input_fn: a generator function that yields input data as a list or tuple,
# which will be used to execute the converted signature to generate TensorRT
# engines. Example:
def my_input_fn():
# Let\'s assume a network with 2 input tensors. We generate 3 sets
# of dummy input data:
input_shapes = [[(1, 16), (2, 16)], # min and max range for 1st input list
[(2, 32), (4, 32)], # min and max range for 2nd list of two tensors
[(4, 32), (8, 32)]] # 3rd input list
for shapes in input_shapes:
# return a list of input tensors
yield [np.zeros(x).astype(np.float32) for x in shapes]对 INT8 的支持
相较于 FP32 和 FP16,INT8 需要额外的校准数据来确定最佳量化阈值。当转换参数中的精度模式为 INT8 时,需要为 convert() 方法调用提供输入函数。此输入函数类似于提供至 build() 方法的输入函数。此外,传递至 convert() 方法的输入函数所生成的校准数据应与推理过程中可见的实际数据在统计上相似。
from tensorflow.python.compiler.tensorrt import trt_convert as trt
conversion_params = trt.TrtConversionParams(
precision_mode=trt.TrtPrecisionMode.INT8)
converter = trt.TrtGraphConverterV2(
input_saved_model_dir=input_saved_model_dir,
conversion_params=conversion_params)
# requires some data for calibration
converter.convert(calibration_input_fn=my_input_fn)
# Optionally build TensorRT engines before deployment.
# Note that this is GPU specific, and as a rule of thumb we recommend building at runtime
converter.build(input_fn=my_input_fn)
converter.save(output_saved_model_dir)
示例:ResNet-50
本文其余部分的工作流将采用 TensorFlow 2.x ResNet-50 模型,对其进行训练、保存、使用 TF-TRT 优化,以及最后部署,用于推理。我们还将在 FP32、FP16 和 INT8 三种精度模式下使用 TensorFlow 原生与 TF-TRT 比较推理吞吐量。
示例的前提条件
- Ubuntu OS
- Docker (https://docs.docker.com/get-docker)
- 最新 TensorFlow 2.x 容器:
- docker pull tensorflow/tensorflow:latest-gpu
- NVIDIA Container Toolkit (https://github.com/NVIDIA/NVIDIA-docker),这允许您在 docker 容器中使用 NVIDIA GPU。
- 安装在主机上的 NVIDIA Driver >= 450(编写时,应检查最新 tensorflow 容器的要求)。您可以运行以下命令检查您的计算机上当前安装的版本:nvidia-smi | grep “Driver Version:”
- NVIDIA Driver >= 450
https://docs.nvidia.com/datacenter/tesla/tesla-installation-notes/index.html
使用 TensorFlow 2.x 容器训练 ResNet-50
首先,需要从 TensorFlow GitHub 仓库下载 ResNet-50 模型的最新版本:
# Adding the git remote and fetch the existing branches
$ git clone --depth 1 https://github.com/tensorflow/models.git .
# List the files and directories present in our working directory
$ ls -al
rwxrwxr-x user user 4 KiB Wed Sep 30 15:31:05 2020 ./
rwxrwxr-x user user 4 KiB Wed Sep 30 15:30:45 2020 ../
rw-rw-r-- user user 337 B Wed Sep 30 15:31:05 2020 AUTHORS
rw-rw-r-- user user 1015 B Wed Sep 30 15:31:05 2020 CODEOWNERS
rwxrwxr-x user user 4 KiB Wed Sep 30 15:31:05 2020 community/
rw-rw-r-- user user 390 B Wed Sep 30 15:31:05 2020 CONTRIBUTING.md
rwxrwxr-x user user 4 KiB Wed Sep 30 15:31:15 2020 .git/
rwxrwxr-x user user 4 KiB Wed Sep 30 15:31:05 2020 .github/
rw-rw-r-- user user 1 KiB Wed Sep 30 15:31:05 2020 .gitignore
rw-rw-r-- user user 1 KiB Wed Sep 30 15:31:05 2020 ISSUES.md
rw-rw-r-- user user 11 KiB Wed Sep 30 15:31:05 2020 LICENSE
rwxrwxr-x user user 4 KiB Wed Sep 30 15:31:05 2020 official/
rwxrwxr-x user user 4 KiB Wed Sep 30 15:31:05 2020 orbit/
rw-rw-r-- user user 3 KiB Wed Sep 30 15:31:05 2020 README.md
rwxrwxr-x user user 4 KiB Wed Sep 30 15:31:06 2020 research/如前一部分所述,本示例将使用 Docker 存储库中的最新 TensorFlow 容器:由于容器中已经包含 TensorRT 集成,因此用户不需要执行任何其他安装步骤。容器的拉取和启动步骤如下:
$ docker pull tensorflow/tensorflow:latest-gpu
# Please ensure that the Nvidia Container Toolkit is installed before running the following command
$ docker run -it --rm
--gpus=\"all\"
--shm-size=2g --ulimit memlock=-1 --ulimit stack=67108864
--workdir /workspace/
-v \"$(pwd):/workspace/\"
-v \"</path/to/save/data/>:/data/\" # This is the path that will hold the training data
tensorflow/tensorflow:latest-gpu
随后即可在容器内部验证是否有权访问相关文件和要针对的 NVIDIA GPU:
# Let\'s first test that we can access the ResNet-50 code that we previously downloaded
$ ls -al
drwxrwxr-x 8 1000 1000 4096 Sep 30 22:31 .git
drwxrwxr-x 3 1000 1000 4096 Sep 30 22:31 .github
-rw-rw-r-- 1 1000 1000 1104 Sep 30 22:31 .gitignore
-rw-rw-r-- 1 1000 1000 337 Sep 30 22:31 AUTHORS
-rw-rw-r-- 1 1000 1000 1015 Sep 30 22:31 CODEOWNERS
-rw-rw-r-- 1 1000 1000 390 Sep 30 22:31 CONTRIBUTING.md
-rw-rw-r-- 1 1000 1000 1115 Sep 30 22:31 ISSUES.md
-rw-rw-r-- 1 1000 1000 11405 Sep 30 22:31 LICENSE
-rw-rw-r-- 1 1000 1000 3668 Sep 30 22:31 README.md
drwxrwxr-x 2 1000 1000 4096 Sep 30 22:31 community
drwxrwxr-x 12 1000 1000 4096 Sep 30 22:31 official
drwxrwxr-x 3 1000 1000 4096 Sep 30 22:31 orbit
drwxrwxr-x 23 1000 1000 4096 Sep 30 22:31 research
# Let\'s verify we can see our GPUs:
$ nvidia-smi
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.XX.XX Driver Version: 450.XX.XX CUDA Version: 11.X |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla T4 On | 00000000:1A:00.0 Off | Off |
| 38% 52C P8 14W / 70W | 1MiB / 16127MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+接下来开始训练 ResNet-50。为了避免花费大量时间训练深度学习模型,本文将使用较小的MNIST 数据集。不过,对于 ImageNet 这样更先进的数据集,工作流也不会发生改变。
# Install dependencies
$ pip install tensorflow_datasets tensorflow_model_optimization
# Download MNIST data and Train
$ python -m \"official.vision.image_classification.mnist_main\"
--model_dir=./checkpoints
--data_dir=/data
--train_epochs=10
--distribution_strategy=one_device
--num_gpus=1
--download
# Let’s verify that we have the trained model saved on our machine.
$ ls -al checkpoints/
-rw-r--r-- 1 root root 87 Sep 30 22:34 checkpoint
-rw-r--r-- 1 root root 6574829 Sep 30 22:34 model.ckpt-0001.data-00000-of-00001
-rw-r--r-- 1 root root 819 Sep 30 22:34 model.ckpt-0001.index
[...]
-rw-r--r-- 1 root root 6574829 Sep 30 22:34 model.ckpt-0010.data-00000-of-00001
-rw-r--r-- 1 root root 819 Sep 30 22:34 model.ckpt-0010.index
drwxr-xr-x 4 root root 4096 Sep 30 22:34 saved_model
drwxr-xr-x 3 root root 4096 Sep 30 22:34 train
drwxr-xr-x 2 root root 4096 Sep 30 22:34 validation获取 TF-TRT 将使用的 SavedModel
经过训练,Google 的 ResNet-50 代码将以 SavedModel 格式导出模型,路径如下:checkpoints/saved_model/。
以下示例代码可以作为参考,以将您自己的训练模型导出为 TensorFlow SavedModel。
import numpy as np
import tensorflow as tf
from tensorflow import keras
def get_model():
# Create a simple model.
inputs = keras.Input(shape=(32,))
outputs = keras.layers.Dense(1)(inputs)
model = keras.Model(inputs, outputs)
model.compile(optimizer=\"adam\", loss=\"mean_squared_error\")
return model
model = get_model()
# Train the model.
test_input = np.random.random((128, 32))
test_target = np.random.random((128, 1))
model.fit(test_input, test_target)
# Calling `save(\'my_model\')` creates a SavedModel folder `my_model`.
model.save(\"my_model\")- 代码
https://tensorflow.google.cn/guide/keras/save_and_serialize#savedmodel_format
我们可以验证 Google 的 ResNet-50 脚本生成的 SavedModel 是否可读和正确:
$ ls -al checkpoints/saved_model
drwxr-xr-x 2 root root 4096 Sep 30 22:49 assets
-rw-r--r-- 1 root root 118217 Sep 30 22:49 saved_model.pb
drwxr-xr-x 2 root root 4096 Sep 30 22:49 variables
$ saved_model_cli show --dir checkpoints/saved_model/ --tag_set serve --signature_def serving_default
MetaGraphDef with tag-set: \'serve\' contains the following SignatureDefs:
The given SavedModel SignatureDef contains the following input(s):
inputs[\'input_1\'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 28, 28, 1)
name: serving_default_input_1:0
The given SavedModel SignatureDef contains the following output(s):
outputs[\'dense_1\'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 10)
name: StatefulPartitionedCall:0
Method name is: tensorflow/serving/predict验证 SavedModel 已正确保存后,我们可以使用 TF-TRT 进行加载以开始推理。
推理
使用 TF-TRT 执行 ResNet-50 推理
本部分将介绍如何使用 TF-TRT 在 NVIDIA GPU 上部署保存的 ResNet-50 模型。如前所述,首先使用 convert 方法将 SavedModel 转换为 TF-TRT 模型,然后加载模型。
# Convert the SavedModel
converter = trt.TrtGraphConverterV2(input_saved_model_dir=path)
converter.convert()
# Save the converted model
converter.save(converted_model_path)
# Load converted model and infer
model = tf.saved_model.load(converted_model_path)
func = root.signatures[\'serving_default\']
output = func(input_tensor)为简单起见,我们将使用脚本执行推理 (tf2_inference.py)。我们将从 github.com 下载脚本,并将其放在与先前相同的 docker 容器的工作目录 “/workspace/” 中。随后即可执行脚本:
$ wget https://raw.githubusercontent.com/tensorflow/tensorrt/master/tftrt/blog_posts/Leveraging%20TensorFlow-TensorRT%20integration%20for%20Low%20latency%20Inference/tf2_inference.py
$ ls
AUTHORS CONTRIBUTING.md LICENSE checkpoints data orbit tf2_inference.py
CODEOWNERS ISSUES.md README.md community official research
$ python tf2_inference.py --use_tftrt_model --precision fp16
=========================================
Inference using: TF-TRT …
Batch size: 512
Precision: fp16
=========================================
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
TrtConversionParams(rewriter_config_template=None, max_workspace_size_bytes=8589934592, precision_mode=\'FP16\', minimum_segment_size=3, is_dynamic_op=True, maximum_cached_engines=100, use_calibration=True, max_batch_size=512, allow_build_at_runtime=True)
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
Processing step: 0100 ...
Processing step: 0200 ...
[...]
Processing step: 9900 ...
Processing step: 10000 ...
Average step time: 2.1 msec
Average throughput: 244248 samples/sec- tf2_inference.py
https://github.com/tensorflow/tensorrt/blob/master/tftrt/blog_posts/Leveraging%20TensorFlow-TensorRT%20integration%20for%20Low%20latency%20Inference/tf2_inference.py - github.com
https://raw.githubusercontent.com/tensorflow/tensorrt/master/tftrt/blog_posts/Leveraging%20TensorFlow-TensorRT%20integration%20for%20Low%20latency%20Inference/tf2_inference.py
同样,我们可为 INT8 和 FP32 运行推理
$ python tf2_inference.py --use_tftrt_model --precision int8
$ python tf2_inference.py --use_tftrt_model --precision fp32使用原生 TensorFlow (GPU) FP32 执行推理
您也可以不采用 TF-TRT 加速,运行未经修改的 SavedModel。
$ python tf2_inference.py --use_native_tensorflow
=========================================
Inference using: Native TensorFlow …
Batch size: 512
=========================================
Processing step: 0100 ...
Processing step: 0200 ...
[...]
Processing step: 9900 ...
Processing step: 10000 ...
Average step time: 4.1 msec
Average throughput: 126328 samples/sec
此运行使用 NVIDIA T4 GPU 执行。同样的工作流可以在任何 NVIDIA GPU 上运行。
原生 TF 2.x 与 TF-TRT 推理性能对比
借助 TF-TRT,只需进行少量代码修改可显著提高性能。例如,使用本文中的推理脚本,在 NVIDIA T4 GPU 上的批处理大小为 512,我们观察到 TF-TRT FP16 的速度几乎比原生 TensorFlow 提升了 2 倍,TF-TRT INT8 的速度提升了 2.4 倍。实际速度提升可能因各种因素而异,如使用的模型、批处理大小、数据集中图像的大小和格式以及 CPU 瓶颈。
我们在本文中展示了 TF-TRT 提供的加速。此外,通过 TF-TRT,我们可以使用完整的 TensorFlow Python API 和 Jupyter Notebook 或 Google Colab 等交互式环境。
支持的算子
TF-TRT 用户指南列出了 TensorRT 兼容子计算图中支持的算子。列表之外的算子将由原生 TensorFlow 运行时执行。
- 算子
https://docs.nvidia.com/deeplearning/frameworks/tf-trt-user-guide/index.html?ncid=partn-31097#supported-ops
我们希望您能亲自尝试,如果遇到问题,请在 Github 上提 issue。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。

